Using Dinov3 Search to Identify Fonts in Historical Arabic Books
blogging
til
blog/build/project
Building OCR for historical Arabic manuscripts is hard when you don’t know what fonts the text resembles. I built a simple image similarity pipeline using DINOv3 and Qdrant to match page scans against 300 Arabic fonts — and found one font dominates 93% of pages.
I’ve been working on an OCR model for historical Arabic manuscripts, and one major challenge is that the scripts look very different from modern digital fonts.
To build a good training dataset, I needed to know which fonts most closely match the handwriting style in these old books.
Most online font detection tools failed completely, so I came up with a simple matching pipeline:
- Take a sample from an existing dataset that includes both page images and their text references
- Download ~300 Arabic fonts (e.g. via Google Fonts API)
- For each page image, render the same text using every font, at the same image size
- Embed all images using DINOv3 and store them in Qdrant
- Run a similarity search: the closest matches reveal which fonts look most like the original
The Arabic Fonts
And it worked! The results across 100 pages:
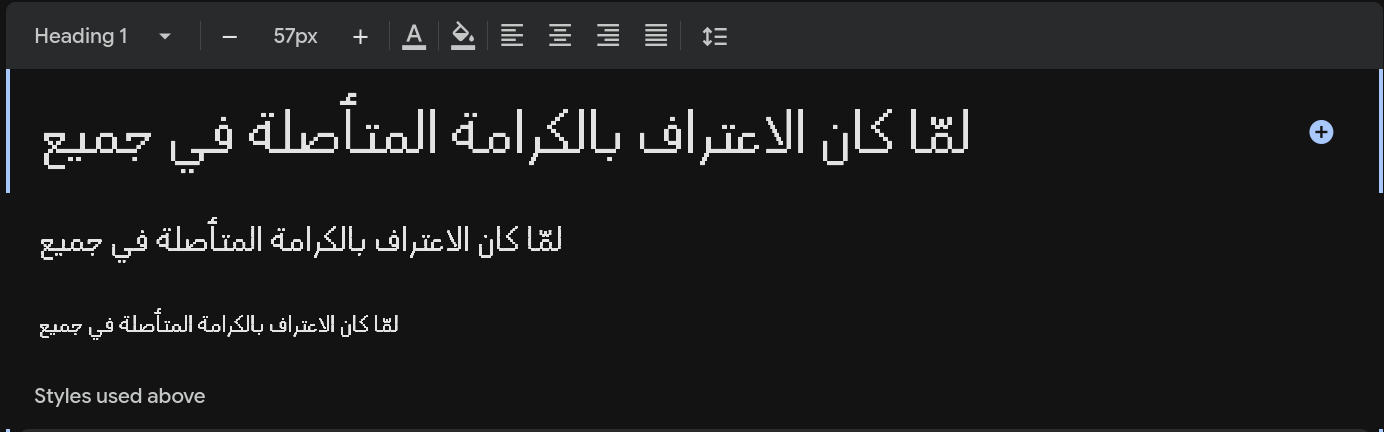
- Reem Kufi Ink Regular: 93 pages (93%)
- Handjet: 6 pages (6%)
With the dominant font identified, I can now generate a large synthetic dataset of (image, text) pairs, giving the OCR model clean, labeled training data.
Reem Kufi Ink Regular
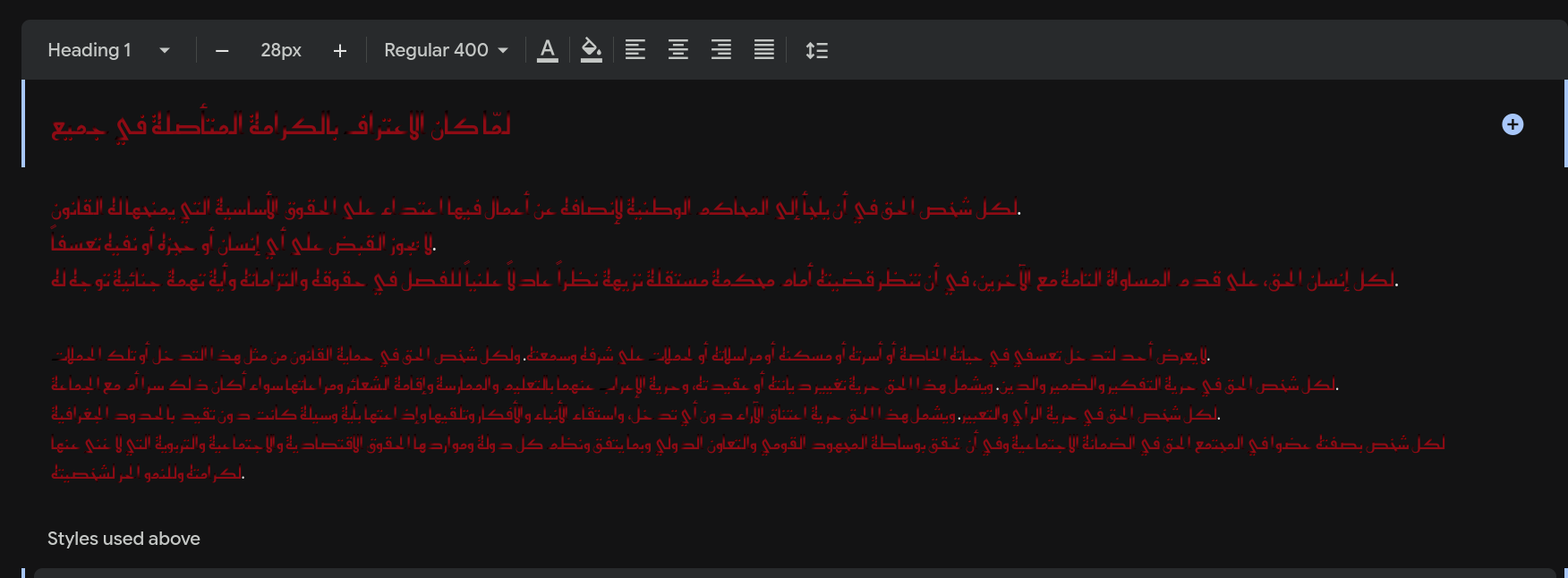
Handjet: 6/100 pages (6%)